


人工智能公司DeepMind宣布了一种AI,该AI可以让您以零规则知识来学习如何赢得胜利,例如围棋,将棋和国际象棋。名为MuZero的AI是朝着自我思考的AI迈出的一大步。
由DeepMind开发的人工智能AlphaGo通过赢得9位世界上最好的骑士Dan Lee而闻名。已经指出,它不适合解决规则不明确的现实问题,因为Alpha Go在Go中具有压倒性的力量,但是它不能解决不确定性很高的问题。
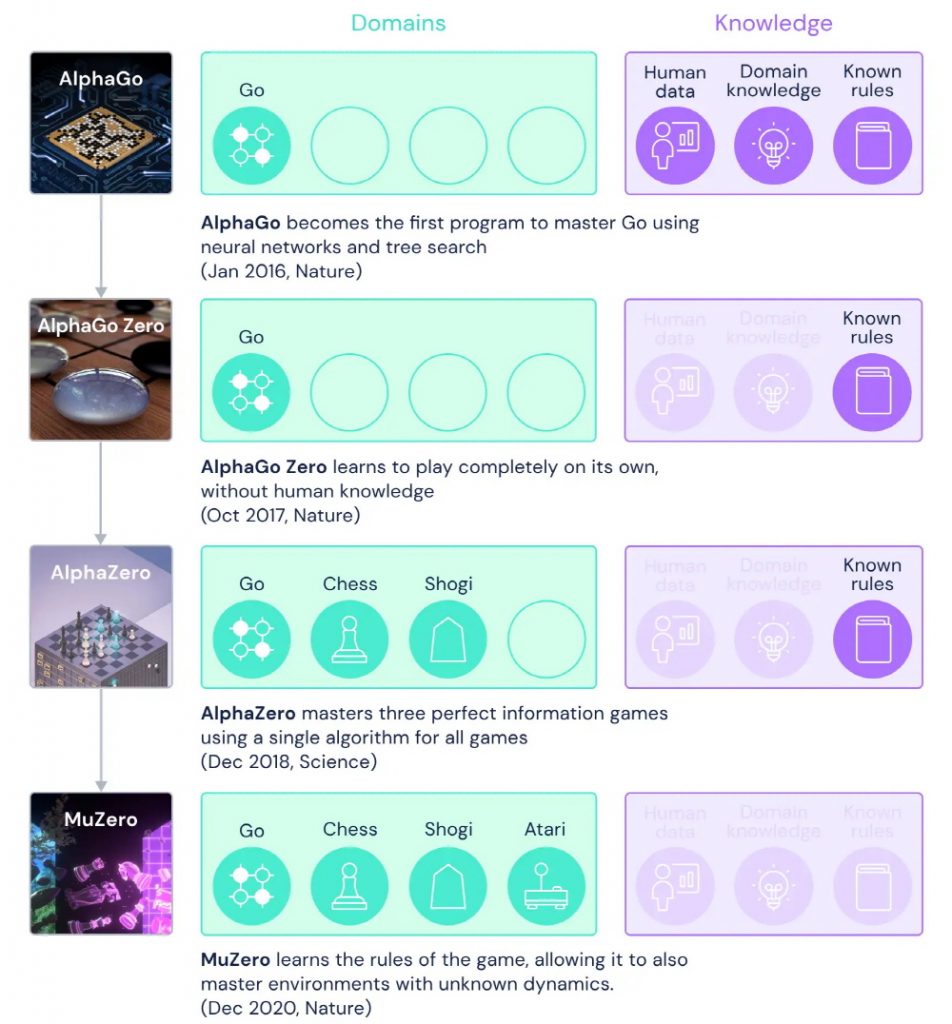
DeepMind新近发布的MuZero是解决AlphaGo挑战的新方法。如果您查看Alpha Go和Alpha Go Zero,Alpha Zero和Mu Zero之间的区别,则Alpha Go仅玩Go,并且需要事先学习人类数据,Go知识,Go规则等。相比之下,MuZero可以通过自我学习来获得最佳解决方案,而无需事先了解围棋,象棋,将棋和Atari。
据解释,在MuZero的开发中使用Atari是为了提供简单的进度指示器,例如游戏分数和丰富的任务,以便玩家制定复杂的策略。 MuZero的目标是训练AI类似于人类对问题的思考,并教育他们解决特定问题。

具体而言,Muzero不使用训练模型就可以对三个元素进行建模。当前头寸的价值,确定哪个动作最好的策略以及确定最后一个动作的效果的收益。
MuZero使用三个因素在神经网络中学习和理解,当采取或计划特定动作时会发生什么。 DeepMind的一方解释说MuZero开发了在MuZero之前玩Atari的人工智能,但是MuZero的性能更高,可与AlphaZero在Go,Chess和Shogi中的表现相媲美。
研究团队希望这项研究的结果将成为开发具有更好问题解决能力的AI的重要一步。相关信息可以在这里找到。