

通过使用机器学习简化服务中的文件预览功能,Dropbox节省了170万美元的成本。
文件预览数据是使用称为Riviera的内部系统预先创建的,该系统可以快速预览上传到Dropbox的文件。但是,在某些情况下,先前的数据没有被使用和浪费,因此启动了Cannes系统,该系统可预测机器学习预先生成的数据,并在生成数据时节省系统资源。
在Carnes的开发过程中,如果预测不正确,开发团队将重点放在性能下降的容忍度和机器学习模型的简单性上。目的是通过在预览允许的范围内绘制一条线来使机器学习精确地绘制该条线。在这方面,据说目标是简化机器学习模型(如果可能的话),以阐明产生预测结果的原因,并促进引言的早期调试。
在机器学习模型的构建中,采用了根据文件扩展名或存储的文件类型进行帐户分类以及最近30天的帐户活动作为输入数据。据说它达到了大约用这种方法制造的戛纳v1的目标,并估计节省了10亿韩元的成本。通过使用生产环境流量等进行A / B测试,开发团队通过实际确认响应速度的下降是否在允许范围内,将Kanes引入了系统。
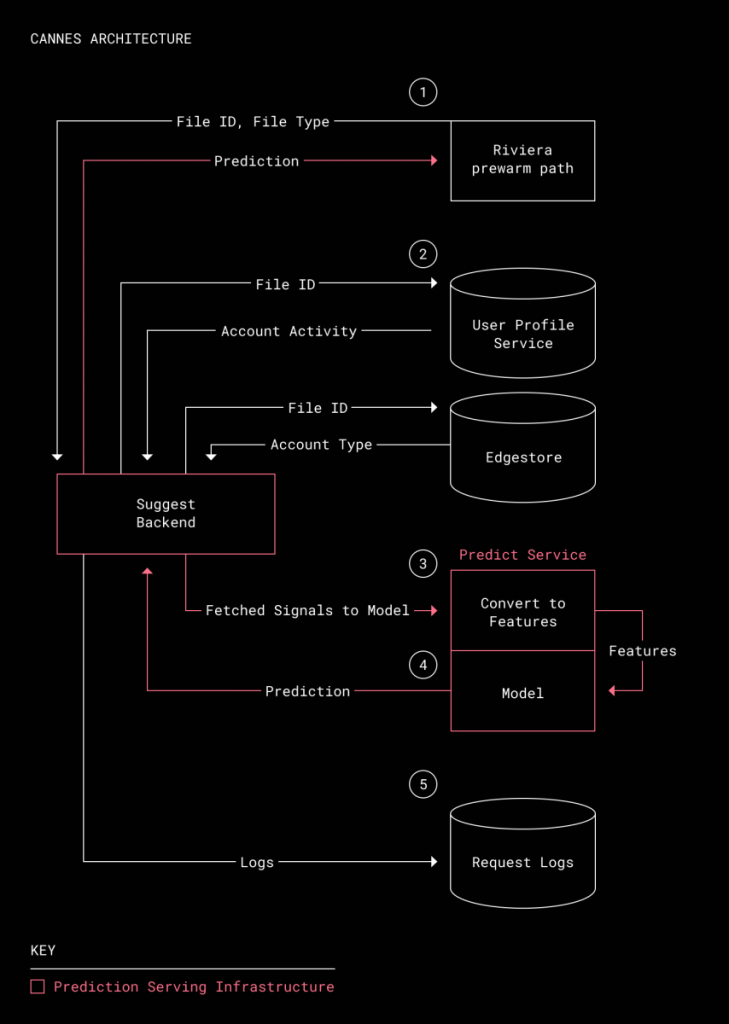
创建预览数据时,负责生成预览数据的Rivera首先将文件ID或类型发送给Carnes。 Carnes根据文件ID从外部数据库收集帐户类型和使用情况。收集的数据被转换成代表特征的向量,然后输入到机器学习模型的模型预测在接下来的60天中是否将执行文件预览,并将预测结果发送到Rivera并作为日志存储。具有调试功能。 。
目前,Carnes已应用于Dropbox上的几乎所有流量,并且开发团队可以像估计的那样大大降低预先生成预览数据的年度成本。 Carnes的运营成本为每年9,000美元,因此可以节省大量成本。除了尝试使用更复杂的模型并提高预测准确性之外,开发团队还计划进行微调,以通过重新学习功能来调整模型。相关信息可以在这里找到。












Add comment