英伟达在 INTERSPEECH 2021 语音技术会议上宣布,它正在开发一种可以发出类似人类表情的人工智能。
合成语音自动导航服务和旧导航导航是机械的。另一方面,安装在智能手机或智能扬声器上的语音助手已经有了很大的发展。但是,真实的人类对话语音和合成语音之间仍然存在很大差异。很容易区分是真人语音还是AI合成语音。根据英伟达的说法,人工智能很难完美地模仿人类声音的复杂节奏和语调。
在英伟达介绍新产品和新技术的视频中,到目前为止,人类一直是叙述者。这是因为,到目前为止,使用语音合成模型可以合成的语音速度和音高控制是有限的,因此不可能像人类叙述者一样说话来刺激观众的情绪。
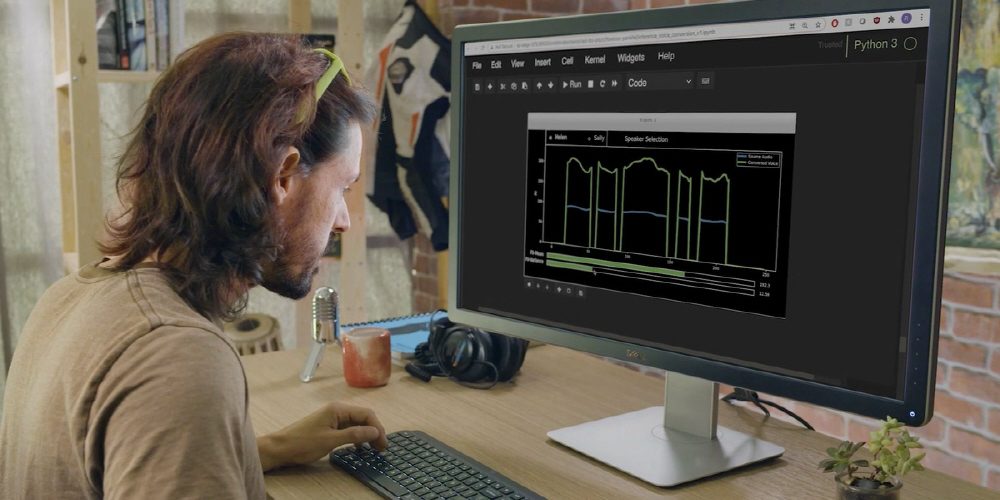
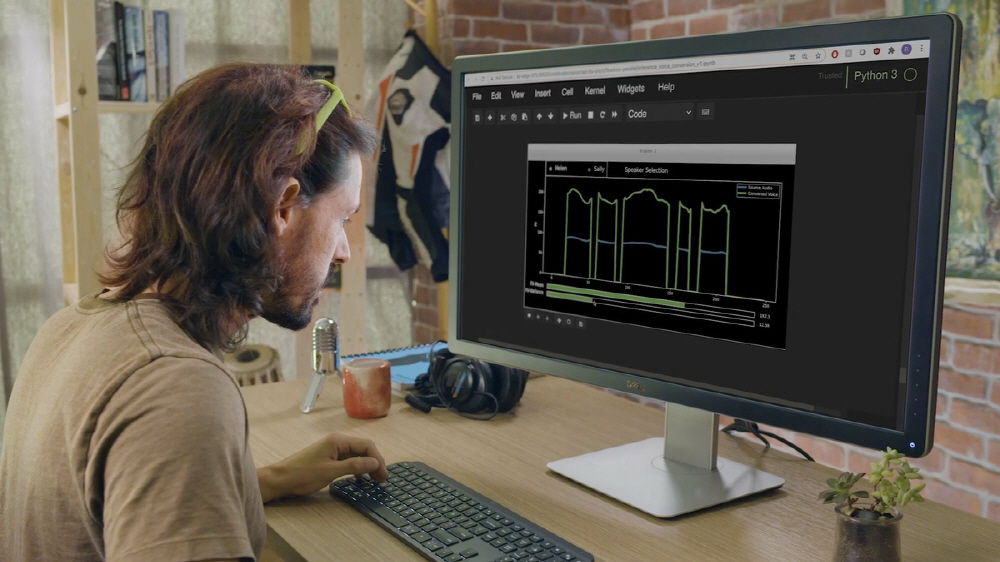
然而,NVIDIA语音合成研究团队开发了一种文本到语音合成技术RAD-TTS,极大地改进了NVIDIA语音合成技术。 NVIDIA NeMo 是 NVIDIA 正在开发的开源交互式 AI 工具包,用于研究自动语音识别和自然语言处理文本到语音合成。人声可以看作是一种乐器,可以逐帧精确控制合成语音的音高、持续时间和强度。
一般来说,机器声音有一种独特的语调,所以有一种不协调的感觉。但是,转换为Nvidia Square的声音播放流畅,没有任何不适。此外,AI 端可以调整合成语音以强调特定单词或更改叙述速度以匹配视频。
除了语音合成解说,他还可以活跃在音乐制作现场。例如,在制作音乐时,您必须在合唱部分录制多个声音并将它们重叠。但是,也可以使用合成声音录制合唱部分而无需收集大多数人。
Nvidia Nemo 中包含的 AI 模型通过从 Nvidia 的 DGX 系统学习数万小时的语音数据,与 Tensor Cores(Nvidia 的 GPU)协同工作。 Nvidia Nemo 还将展示在 Mozilla Common Voice 上训练的模型,该数据集包含 76 种语言的 14,000 小时语音数据。英伟达表示,它的目标是使用世界上最大的开源语音数据集实现语音技术的民主化。 Nvidia Nemo 在 Github上有一个开源。相关信息可以在这里找到。












Add comment