
SpecAugment是一种允许Google在不使用语言模型的情况下自动识别语音的技术。
Google正致力于自动语音识别技术,该技术可自动识别语音并将其转换为文本,例如Cloud Speech-to-Text。如前所述,规范参数提高了模型在不使用语言模型的情况下自动识别语音的能力。
语言模型是语言中单词和单词关系的数学表示。通过学习单词后面的单词,可以将只是声音的声音转换为有意义的句子。因此,应该根据语言模型训练能够进行自动语音识别的AI。
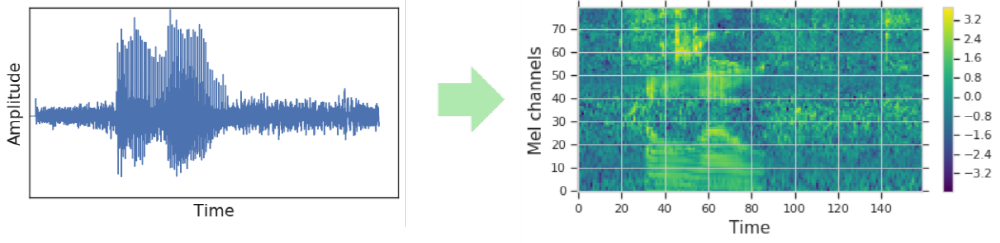
Google研究团队发布的规范组件允许您构建自动语音识别模型,这些模型比传统方法更精确,无需语言模型的帮助。现有的自动语音识别模型将语音数据转换为光谱形式的视觉表示,并将其输入网络模型。识别处理在频谱中执行,但是所提供的数据本身需要大量的语音数据并且需要大量的计算成本。
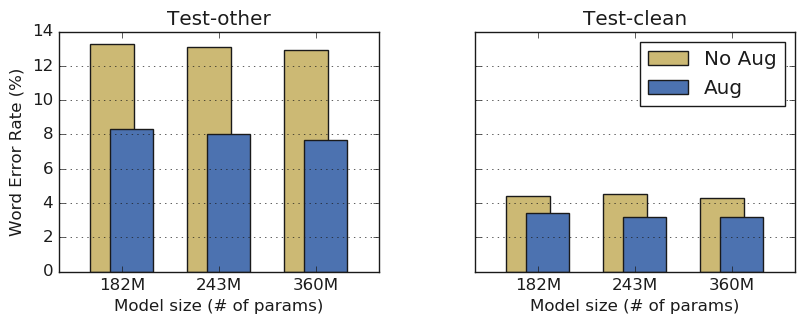
直接编辑光谱数据并掩蔽光谱数据以增强光谱数据。这可以防止过度学习模型,并且能够以比没有语言模型支持的现有模型更高的精度执行语音识别。如果噪声信号为负,则传统自动语音识别模型的识别精度为12~14%,噪声信号为低时为4~5%。使用规范参数的自动语音识别模型在大声语音的情况下约为8%,在小语音信号的情况下约为3%。
如果您拥有此技术支持的自动语音识别模型,您可以在电子邮件听写模式下使用它,或者您可以使用诸如将智能扬声器上的交互式AI语音转换为文本。如果识别率低,则可以迅速输入语音而不是用实际手指键入。欲了解更多信息,请点击这里 。












Add comment