

只有发言者的声音可以识别性别,年龄,甚至你来自哪里等信息。 Speech2Face是一种人工智能,可以在预期人类语音和语音的情况下生成图像。正在开发它以从语音中获得人的身体特征。
Speech to Face是一个在YouTube上传的视频,用于教授机器有关演讲者的年龄,性别,种族,声音和声音,并在语音中生成人脸的图像。该研究中使用的视频达数百万次,而言语传达已经吸收了超过10万人的声音和面孔。
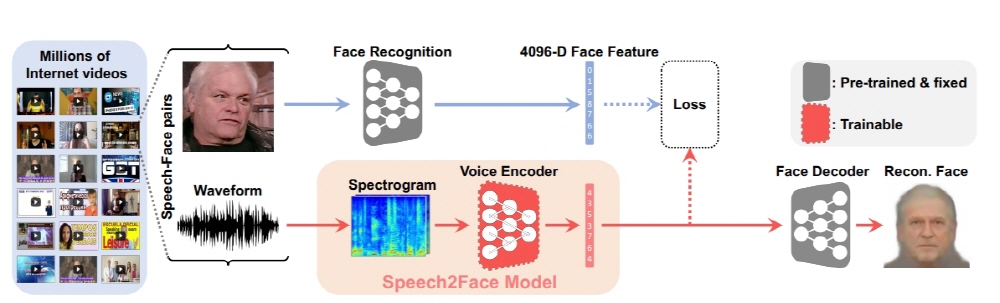
实际上,语音对面实际上将语音生成的面部图像与实际面部进行比较,但种族,性别和年龄相似,但细节不同。此外,脸部产生的面对面图像都是无表情的。
根据这项研究,面对面的图像主要是年龄,种族和性别,声音输入的时间越长,它就越准确,但它并不完美。即使同一个人分别从说中文的声音和说英语的声音创建面部图像,白色图像由英语产生,亚洲图像由中文产生。此外,在低音的情况下,男性倾向于产生女性的图像和高音。欲了解更多信息,请点击这里 。












Add comment