近来,由于人工智能歧视和偏见的可能性处于危险之中,Facebook人工智能领域的首席研究员因使用人工智能算法辨别图像而受到批评,并且Twitter帐户已被暂停。在训练神经网络的过程中,使用了一个数据集,但研究人员自己删除了一个已经使用了10年以上的大型数据集,称此数据集正在引起歧视。
通过机器学习训练的AI会读取人类在训练过程中创建的数据集。尽管AI本身不会产生歧视和偏见,但它是一种基于数据集学习的结构,因此AI继承了数据集中包含的歧视和偏见。
例如,通过机器学习训练的AI倾向于将花朵和音乐与乐趣相关联,而不是将错误和武器与乐趣相关联。同样,尽管女人这个词与艺术性有关,但与数学的联系却往往很困难。长期以来已经指出了该问题,并且创建不反映人类歧视的数据集变得重要。
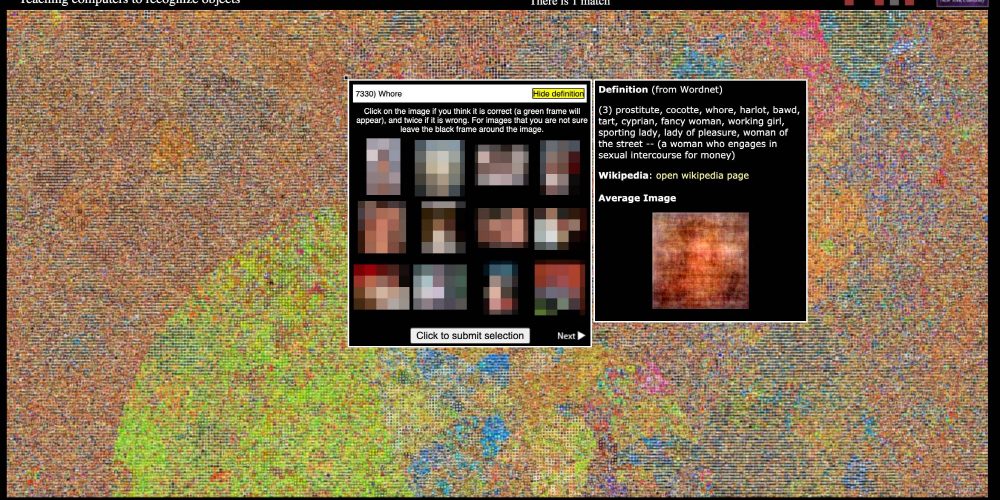
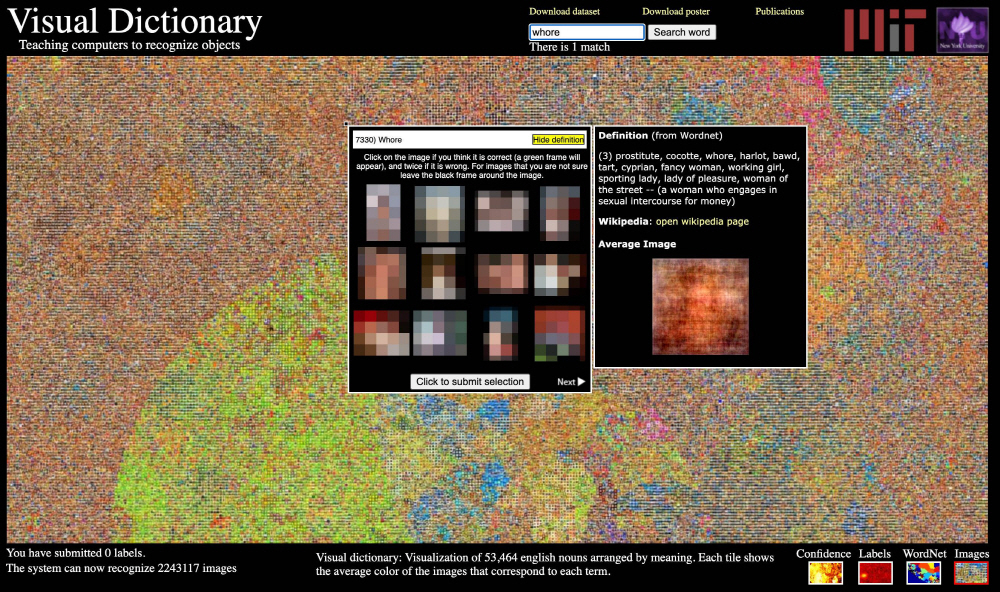
麻省理工学院在2008年创建了一个名为Tiny Images的图片库,该图片库使用了800亿张照片。该图像库链接照片和主题名称标签,并用于计算机培训。但是,开发下一代身份验证服务的UnifyID的首席科学家Vinay Prabhu和都柏林大学的博士生Abba Birhane调查了Tiny图像,发现成千上万的图像是亚洲图像。还有黑人歧视用语,被发现使用错误的标签来形容女性。
数据集包括按黑色歧视术语分类的猴子照片,泳衣中被标记为妓女的妇女照片以及分类为淫秽的解剖部位。建立这种关联后,依赖神经网络进行Tiny图像训练的应用,网站和产品指出了在分析照片和视频时使用此术语的可能性。
对此,麻省理工学院在6月29日(当地时间)完全在线删除了Tiny图片。麻省理工学院认为,这是因为在Tiny图像数据集中包含不适当术语的数据集依赖于英语概念词典(WordNet)自动生成的数据收集。由于数据集很大并且图像很小(32×32像素),因此手动过滤很困难,因此研究人员决定从互联网上删除数据集本身,而不是添加校正。
同时,IBM在6月宣布将退出面部识别市场,因为它担心技术会加剧歧视和不平等现象。人脸识别软件已在许多国家/地区用于刑事调查,但同时也指出,它也存在数据集问题,由于黑色身份验证的准确性较低,因此可能导致错误逮捕。相关信息可以在这里找到。












Add comment