

谷歌旗下的人工智能公司DeepMind开发了popart(PopArt),这种技术可以通过人工智能弥补多任务学习的回报。
深入思考开发了人工智能AlphaGo,它将人工智能热潮带到了韩国的第9阶段,并开发了DQN,这是一种人工智能,通过学习强化学习来比人类更好地学习游戏。
这就是Deep Mind这次开发流行艺术的原因。需要多任务学习以允许一个代理学习如何解决多个任务。多任务学习是人工智能研究的长期目标之一。诸如上面提到的DQN之类的代理也使用可以自己学习并且在玩多个游戏时学习多任务处理的算法。随着人工智能研究变得越来越复杂,目前在相关研究中安装各种专业代理是主流。
在这种情况下,学习多个代理的算法应该能够通过单个代理构建多个任务。多任务学习算法变得重要。但是,这种多任务学习算法存在问题。强化学习代理使用不同的补偿因子来确定成功。
我们来举个例子吧。如果在DQN中学习游戏乒乓,则代理接收每个学习阶段的-1,0,+ 1中的一个。但是如果你学习吃豆人,你可以在每个学习阶段获得数百或更多的奖励。使用相同的补偿标度,您无法测量哪些任务更重要。
即使个别补偿金额相同,补偿频率也可能不同。代理商倾向于关注更大的奖励,因此不同的薪酬等级和频率可以导致某些任务的更高性能和其他任务的更低性能。
要解决这个问题,无论每场比赛可以获得多少补偿,您都必须标准化游戏特定赔偿金额,以便座席能够将游戏判断为相同的学习价值。那是流行艺术。
根据Deepmind的说法,将波普艺术应用于最新的强化学习代理已经导致创建了一个可以同时学习超过57种不同游戏的代理。
深度运行会更新神经网络权重,以使输出接近目标值。在深度强化学习中使用神经网络时也是如此。因此,流行艺术通过估计目标游戏得分的平均值和渗透率来标准化得分,并且根据该改变实现稳定学习。
到目前为止,强化学习算法已经尝试通过使用补偿削波来克服补偿缩放的问题。较高的分数是+1,较小的分数是-1,依此类推。通过补偿剪辑,可以简化代理学习,但代理不执行特定操作。使用传统补偿裁剪的多任务学习不是最佳选择。
再举一次,例如,Pacman的游戏目标是尽可能高的得分。有两种方法可以从Pac-Man获得积分。一个是在舞台上吃东西,另一个是吃东西和吃怪物。刚吃普通物品10分,吃怪物200-1,600分。
在这种情况下,当使用补偿剪辑时,不可能找到正常项目获得的点与吃掉怪物时的点之间的差异。你不想吃怪物来获得更高的分数。
应用波普艺术代替补偿剪辑可以认识到吃怪物很重要,因为补偿是标准化的。
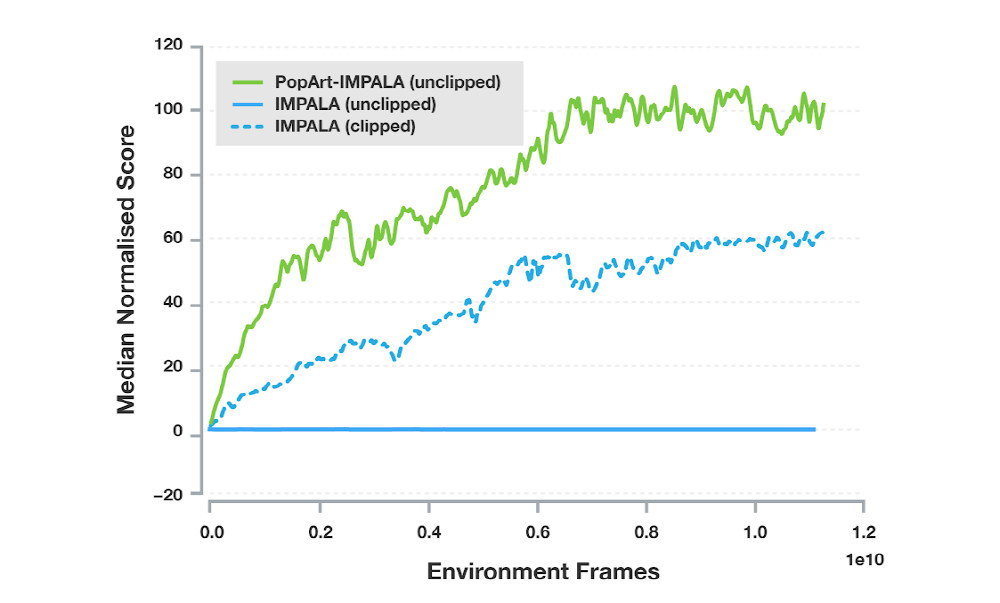
由于将流行艺术应用于IMPALA,这是Deep Minds使用的最受欢迎的代理之一,因此代理性能得到了极大的提升。 Deep Mind表示,这是多任务环境中第一次通过单一代理实现高性能,并且当使用各种奖励学习代理用于各种目的时,Popart将付出巨大努力。
波普艺术的出现有望在人工智能研究中发挥巨大作用,人工智能变得越来越复杂。通过代理人的学习经历了奖励代理人的过程,就好像在学习马戏团时给动物一个好的马戏团。在这方面,流行艺术等标准化奖励似乎有相当大的帮助。有关更多信息,请单击此处 。












Add comment